It's been a long time since I created a website from scratch. The year was (probably) 1999, tables and frames were all the rage, and I was 11 with a
passion for garish clipart and comic sans. Luckily for everyone, I didn't actually have an internet connection at the time: my first and, until now, only custom-build page was a local affair.
Then the early 2000s came, the social web revolution, myspace, blogs, wordpress: I didn't need to write any HTML, and I learned CSS only by trying to make simple tweaks on
the free templates of early blogging services (first with blogspot, later with a custom install of wordpress). Again, luckily, all those things are lost to the ether (or, at least, very hard to find).
So, in mid-2021, why would I want to go back to the ides of 1999? Surely it would be easier to just use any of the myriad CMS available?
Well, yes and no.
I've had this domain since 2018. All that time, I had an instantiation of wordpress, a title page, and a couple of headings. No content other than the stereotypical Lorem Ipsum. CMS are lazy. I am lazy. The result was a boring,
ugly, dead page that still showed up when people googled my name.
A few weeks ago I also decided it was time to brush up on my coding skills: I have kept them up haphazardly, on a "learn-only-what-you-need-to-know" basis, which has been great for breadth of knowledge, but less brilliant on actually
getting anything done. I've signed up for freeCodeCamp in which the first block of lessons was on web development. The last test in that block was to build a personal portfolio. I
phoned it in for the test, doing only the bare minimum, but decided it was time to do it for real. That was the moment when this version of tiagosousagarcia.co.uk was born.
Concept
The concept for this site was relatively simple: it is mostly modelled on typical academic pages (with sections on research interests, publications), mixed with a professional portfolio
borrowed from the personal spaces of frontend devs, and a chunky section dedicated to my photography. I wanted the site to be static, partly for longevity reasons (in the spirit of endings compliance, though this site is not fully compliant yet), partly to keep it light and quick(ish), mostly to allow me to dive deep into all aspects of its creation.
For the most part, I wanted a single-page site, with more detailed information on projects and the photography portfolio relegated to their own single-page minisite.
Migrating from the world of digital textual editing and the Text Encoding Initiative (itself an XML based language), I knew I wanted to keep my HTML as semantic as possible. The base HTML
should make perfect sense in itself (at least that's the hope): the <main> content of the website is divided into <section>s, each of which might have one or more <article>s, each
with potential for further nested <section>s and <article>s. A specialist in semantic HTML might balk at my liberal interpretation of the standard, but for a textual editor this structure should make
sense: each top-level <section> akin to a chapter, each second-level <section> a subsection of that chapter. The result is that, with the exception of the photography portfolio which is mostly a visual
medium, there is no meaningless <div> anywhere to be seen in the code. Whether that is a good or a bad thing is another story.
Design
Having settled on a one page structure (for the most part), then came the hardest bit: the design of the page. I knew, from the start, a few things that I wanted for the basic page:
A strong but minimalistic, full page header;
Simple, nearly monochromatic, colour-scheme;
A fixed navigation bar.
All of these were imminently doable, but things got more complicated when my ultimate goal of responsiveness came into play: I had never designed anything responsive in my life -- that was one of the joys of using CMS in
the past. That's when I started to learn about flexbox and the joys (and pains) of mobile-first design. That experience came too late for the bulk of the main page -- which is now a rather messy affair in desperate need of a
re-write -- but proved invaluable when I tackled the design of the photography portfolio for the second time.
The (nearly) monochromatic colour-scheme is indebted to my photography as well: I shoot mostly film, mostly in black and white, so it seemed reasonable that my site would follow the same visual language. There are only two accent colours
to break the monotony: the blue of the headings and the red of the graphical flourishes -- everything else
appears in shades of white or black.
Typography was kept as simple as possible (some might call it boring). As the vast majority of the web, this site makes use of Google Fonts, specifically three sans-serif font
families: page titles are in Raleway, headings, navigation menu, and other higher-level textual elements are in Montserrat,
and everything else uses 'Poppins.' The differences between each are minimal, but that's the point.
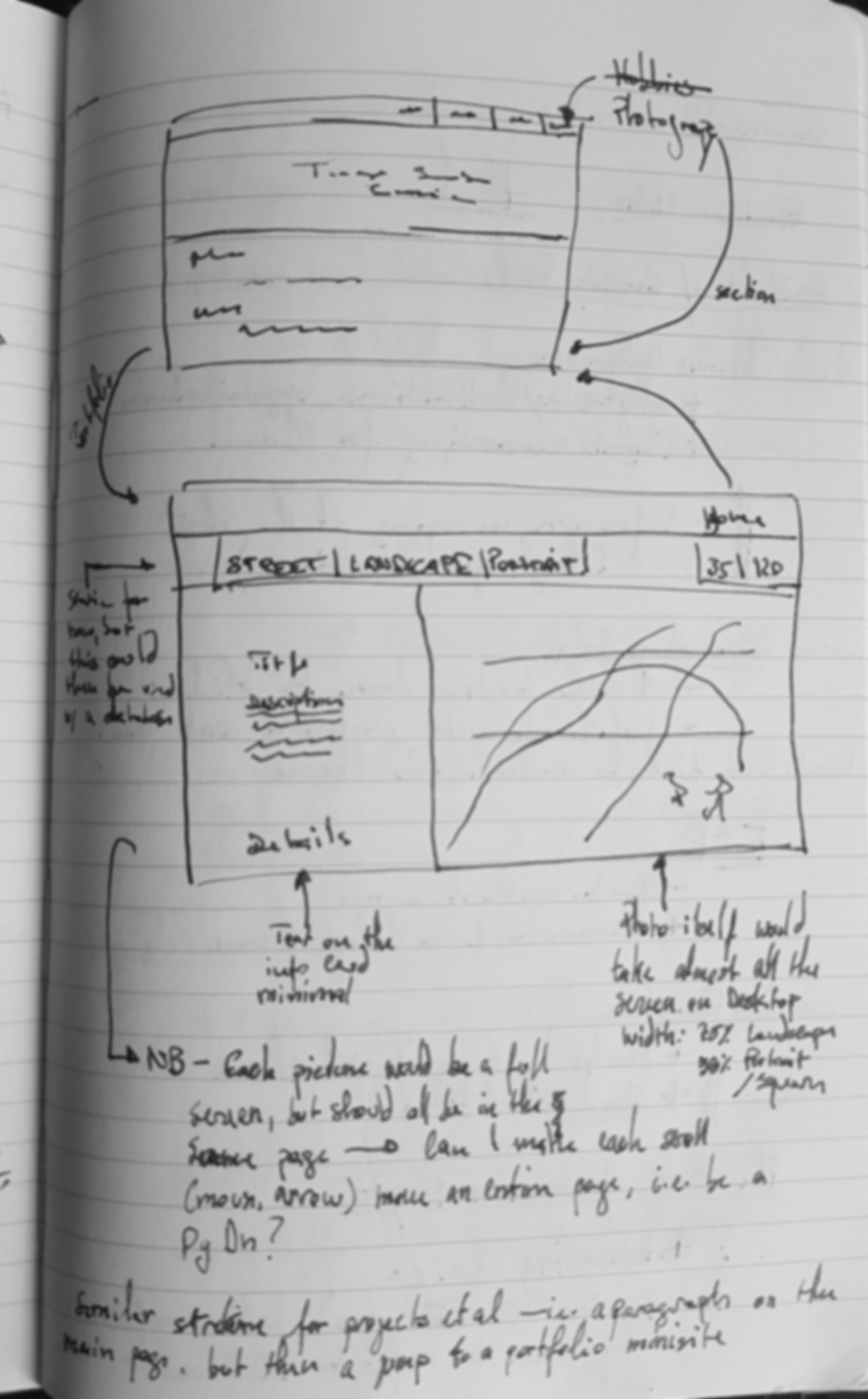
Designing the Photography Portfolio
Handrawn wireframe for the photography portfolio
At the risk of sounding immodest, I am very proud of the design of the photography portfolio. I had one of those rare moments of inspiration one night when I couldn't sleep. Its
concept is quite simple: it borrows the language of a photography book. With widescreens (or basically, anything larger than a smartphone), each viewport is a page-opening, with each photograph occupying roughly half the screen, and as
tall as possible without affecting its native ratio. On a desktop, I wanted each scroll motion to be like a page-turn. The challenging bit was, again, to make this vision mobile-friendly: I knew how I wanted the design to transfer
to
a smaller screen (a straight column, with each screen having the full image and the accompanying text), but I had no idea how to do it.
The first draft of the portfolio was a nightmare to transfer to a mobile site: nothing worked, my carefully considered layout kept breaking at different, and apparently random, points. I scrapped the whole thing and started again, using
flexbox for everything, and eschewing the problematic mandatory scroll points.
The final result is not perfect, but it is faithful to my initial idea, with only a handful of concessions.
Final thoughts
Would I do this whole thing again?
Yes, I would. Designing this website has been fun, challenging, and rewarding. There was a time in which I might have given up at the first hurdle, but I am much more knowledgeable now than I was when I did this sort of thing
for a living. I had too much fun figuring out how to create animated cards (as you can probably see from the main page), and am way too proud about how the photography portfolio looks. It might not be perfect, but it is a good-looking
place. I made a point of using only my own photography to illustrate it, and whenever that wasn't possible, I created simple graphics to illustrate certain sections.
Everything in this website (with the exception of the photographs
themselves) is free to reuse, offered under a CC-By license -- though I doubt anyone would find any particular use for my rough CSS. The photos are under copyright
but if you see anything you like (here or on my instagram) get in touch, I'm sure we can sort something out.
Not that it matters at all, but in case you are curious, the entire website was developed using Atom, and only too late in its development have I discovered the magic of Emmet.
ATNU projects
I joined Animating Text Newcastle University (ATNU) in late 2017 as a Research Associate. ATNU is a research project that brought together humanists, computers scientists and
research software engineers to explore digital ways of researching, exploring, and interacting with humanities' data in textual form. ATNU's main function was to experiment with, and
push the boundaries of, digital humanities. ATNU eventually grew to encompass a healthy and diverse group of researchers, but most of the conceptual digital work was
undertaken by me and James Cummings, with Jennifer
Richards leading the whole thing. Most of the actual coding was done by the wonderful RSE Team, in particular by Fiona Galston, Kate Court, and Mark Turner.
My role in the project, in addition to that of a general dogsbody, was to serve as a bridge between researchers in the humanities, for the most part without any technical abilities, and the RSE team, as well as to serve as a consultant to
academic colleagues about the digital possibilities of their research projects, helping them to develop an interesting and (hopefully), significant contribution to Digital Humanities. The projects were varied, and my contribution to each
equally varied, from a simple sounding board, to doing some textual encoding, or even creating simple but functioning prototypes (as is the case with the Writing with AI project below).
The study of the correspondence network of David Bailie Warden. The project was led by Jennifer Orr, the textual encoding and network
visualisations by Sharon Howard.
An experiment in how to visualise the complex composition history of contemporary poetry, including multiple parallel drafts, print proofs, and recorded live readings. The project was led by Mark Byers, Sinead Morrissey, and Linda Anderson. I did the textual encoding.
Manuscripts after Print was an AHRC funded research project led by Aditi Nafde. As part of that project, ATNU developed a Hands-on Reading app, a web application that allows users to read and freely annotate a portion of the Canterbury Tales in a simulation of an early printed book.
An interactive, chronological map tracing the European translations of the works of the early feminist Mary Wollstonecraft, led by Laura Kirkley. As well as general consulting and data wrangling, I also created an early prototype of the project using the now (sadly)
non-existent Google Fusion Tables.
Taking the mission of ATNU a little too literally, this is an animation of an early modern engraving describing a new form of balloting proposed by James
Harrington. The project was led by Rachel Hammersley.
An interface to study the influence of prosodic and rethorical emphasis in voiced readings of early modern texts, using a text-to-speech engine (specifically Amazon's Polly).
The project was led by Jennifer Richards.
A digital edition of the Sarum Hymnal, including facsimiles, metadata, and an experimental navigation of the hymns through the liturgical calendar. The project was led by Magnus Williamson.
Coopers Hill is a seventeenth century poem written by the royalist poet and courtier Sir John Denham, between the early 1640s and the mid 1650s.
The poem is Denham's most famous work, though its fame waned drastically since the time of its first publication. Denham was also a playwright and a translator, publishing (as many of his contemporaries did) a version of the
Aeneid.
Like many of his contemporaries, Denham's work and career is largely tied to the tremendous political and social upheavel of their time, the Civil War. Denham is
usually identified with the royalist group (i.e., those who sided with the King and opposed Parliament) though, as many historians have noted, such gross generalisations are just that. Given the bad fortune of the royalist side during the
conflict, Denham eventually left England at the end of the 1640s to join the exiled court in Paris, returning home in the early 1650s, penniless. He would not recover his status until after the Restoration, though he died at the end of the decade, in 1669 at the age of 54, suffering at that time from what we now understand (and believe to have been) as
dementia.
Coopers Hill is worthy of attention, not only because it is Denham's most famous poem but also for its curious relationship with the period and complexity of its composition.
The poem is one of the first (if not the first) of so-called topographical poems, a subgenre of poetry that deals mostly with the description and
praise of place. In the case of Denham's work, that place is the titular Cooper's Hill, Surrey, near Windsor and Runnymede, the place where the Magna Carta was signed in 1215. The poem's speaker climbs to the top of the hill and uses the landscape around it to muse on British History until
that point in time: from its Roman History, Danish and Norman invasions, the signing of the Magna Carta and the much more recent events of the break with Rome and dissolution of the monasteries under Henry VIII. Throughout the retelling of
British (specifically English) history and the observation of place, the tenor of Denham's speaker is distinctively royalist in outlook: though that outlook does not remain stable throughout the entire history of the poem.
Coopers Hill is particularly noteworthy for its composition and publication history. The poem was first published in 1642 (though it likely circulated in manuscript before that date), and goes on to be published at least five more
times, in 1643, 1650, 1653 (of which only one copy is known), 1655, and 1668. The interesting thing is that, of those six editions (if you forgive the anachronism), no two are alike; more so between the 1650 and the 1655 edition,
when
the poem goes through a significant rewriting that alters its reading in a major way.
The keen-eyed probably noticed that a major development took place between 1650 and 1653: the royalists finally, and decisively, lost the civil war (specifically in 1651, at the battle of Worcester, of Royal Oak fame). A couple of years before that, England had also, for the first time in history, tried and executed its king for treason. Likely as a direct result of those events (as well as a myriad others, now less clear for modern readers), Denham
rewrote a significant portion of Coopers Hill to the point of creating an entirely new reading, changing the underlying message of the poem from one that seems to warn against revolution to one that regrets its excesses. In other
words, though Coopers Hill has a unique title (and is often presented as a singular poem), it is better understood as (at least) two entirely different texts; or, to put it bluntly, if offers a perfect laboratory of how literature
was affected by the political context of the mid seventeenth century.
The ultimate goal of the Coopers Hill project is to create a fully functional scholarly digital edition of the poem in which
all versions are visible, accessible, and their differences are made clear to the reader through an
interactive interface.
The particular characteristics of Coopers Hill make it a perfect candidate for a digital treatment (if such a qualification was necessary):
the print paradigm is wholly innadequte to communicate textual variance, but utterly useless when faced with significant rewrites of the kind that we see in the various editions of the poem (to the point that a previous editor decided
to print four different whole versions of the poem, one following the other, in its previous major scholarly
edition);
the topographical nature of the poem offers many opportunities to take advantage of the digital realm, from a simple mapping of the location mentioned, to the accompanying contemporary illustrations (when they exist), or modern-day
representations of the locations explored in the poem;
similarly, the poem's reliance on the English historical past, not to mention its intertextuality, opens the opportunity to considerably enrich the edition with additional documents, longer explanatory notes, or links to other resources
and further reading.
A further advantage of opting for a digital scholarly edition rather than a traditional print one when it comes to Coopers Hill needs a little more information about the practice of scholarly editing itself. A fundamental aspect
of scholarly editing is collation, that is the comparison, recording, and selection of all (or as many as possible) known
variants of the text. Traditionally, the collation of early modern texts considers essential only manuscript versions (when they are shown to have authorial authority, or derive from the author's circle), and a handful of print examples
from each possible publication. With Coopers Hill, the ambition is to experiment with total collation (or as near to that as humanly possible), that is the recording and comparison of all known witnesses of the text, both
print and manuscript. It might seem like overkill to want to compare all (likely similar) print copies of the poem, but there are two main reasons for this:
The fact that Coopers Hill was the object of such drastic rewrites, and the nature of early modern printing more generally, raises the possibility that smaller rewrites or autograph corrections made only to a subset of print
copies of a particular edition might remain undiscovered;
Collecting the complete list of possible variants on several early modern print runs will create a valuable dataset that could, possibly, offer a new perspective on early modern printing itself which, so far, has relied on its most
famous, over-examined cases (Shakespeare and his First Folio, in particular) as examples of contemporary practice.
The problem, of course, is that all these print copies are spread throughout the world, and there is no feasible way of undertaking this work in a single period. Even when a project is fully funded by a research body (which,
unfortunatelyt, is currently not the case for Coopers Hill), the work of visiting libraries, examining, transcribing and comparing each textual witness takes time. Working in the digital world offers a slight panacea to this
problem: we can add copies as and when we have a chance to examine, transcribe, and encode them. In other words, the ambition of Coopers Hill is not only to be a scholarly digital edition of the poem, but an iterative
edition, in which the infrastructure remains stable even when more transcriptions and encoded versions of the poem are added. This, then, is the base idea behind the collation project outlined
below.
The Student Edition of Coopers Hill
There is an additional proble with Coopers Hill that this project attempts to solve: if you want to teach the poem to undergraduate (or even postgraduate) students, there is no standard edition of the poem easily available that
presents, at the very least, its two major versions together. The last serious attempt at a scholarly edition was published in 1969 and never republished (though now seems to be available as a print-on-demand option), which means that
students are left with the versions that are sometimes published in anthologies of the period which, more often than not, reprint the post-1655 version.
This was the problem that I faced a couple of years ago, when I first wanted to teach the poem to my second year students on a module about literature and history. The solution? Well, a rough-and-ready digital edition of Coopers
Hill. To be more precise, two separate transcriptions, one from the 1642 text, another from the 1655.
I say, carefully, transcription because there was no effort at collation, regularisation, or standardisation in these versions of the text. Their only objective was to offer a simple, readable text from either edition, together
with some cursory explanatory notes to help their understanding. The layout of the page was also kept as spartan as possible.
The transcriptions were encoded in TEI (as it would be expected), and the HTML was generated using an XSLT transformation, with simple inline CSS styling to save on unnecessary frills. The
encoded versions of both texts, as well as the XSLT transformations are available on my GitHub. You can see the texts my students
read here:
This is an ATNU project led by me in collaboration with James Cummings, developed by Kate Court and Fiona
Galston from Newcastle University's Research Software Engineering Team. The idea for this project grew from a problem I encountered during the conception of the Coopers Hill edition: how can we make preliminary results from textual editing work available, without having to re-encode and re-publish the edition everytime we add a new witness?
The solution we found is a combination of stand-off markup, a user-friendly uploading system, and some rudimentary automatic collation achieved by comparing
the existing witnesses with the newly uploaded encoded transcriptions.
In the specific case of Coopers Hill this works by having a set of stand-off markup archetypes (i.e., one for each edition of the poem) which will collect both annotation and textual variants. These archetypes will be
automatically updated when a new witness is uploaded: each time a new variant is discovered, the system will compare it with existing witnesses that conform to the same archetype (for example, each existing witness for 1642), identify any
line variation, and record its place of variation in the archetype, linking to the original encoded transcription.
This system ensures that, unless major variants are discovered for each archetype, the framework of the edition remains stable whether it includes one or one hundred witnesses, greatly diminishing the work of manually adding each small
variant, reducing the need for constant re-encoding and re-publishing of the edition, while ensuring that the latest version possible is always available to readers.
This systems is currently under development, but its release is imminent! Stay tuned for more.
Writing with AI
Writing with AI is an ATNU project led by me and Laura McKenzie, in collaboration with Seven Stories, the national centre for children's books. At various points, this project was called the Creative Engine, the Writing Wizard, and even The title of the app is the most important
part of it, right?, though this was itself the result of asking an AI what I should call the project. To be perfectly honest, we are yet to find an adequate title for this, so for now we will refer to it with the rather descriptive
and boring Writing with AI.
Essentially, the project is an interface that allows children and young people to interact with a text-generating AI to write a short story. The AI will be trained on archival materials from Seven Stories, and refined to produce writing
suggestions suitable for the younger crowd. It will serve both as a gateway for exploring the Seven Stories' collection, and a study of human and machine creativity.
We are currently working hard behind the scenes to get this project funded and off the ground, but I wrote a very short prototype in Python using the bog-standard version of GPT-2. The code is available on my GitHub, but it requires a certain amount of preparation and
familiarisation with Python to run. If that's you, have a look at it.
Python utilities
There's not much to say about this one: this is a number of small python scripts I wrote to either: a) try out something new, b) learn a new approach or method; or c) get something done. All of them are available on my github. They are an ever shifting collection: the current script that might be of interest to anyone else besides me is the script that
strips speaker labels from Zoom-generated captions (if, like me, you've been hosting speakers, recording their talks, and making them available online.)
AI and Literary Studies
AI and Literary Studies, or Reading Machines, to give it its proper name, is a research network that brings together scholars from literary studies, digital humanities, and computer science, to study how Artificial Intelligence
can play a part in humanities' research.
The ultimate objective of the network is to figure out whether it is possible to create (or train, repurpose, refit) an Artificial Intelligence that can perform the task of reading a text in a way that would more closely resemble what
humans understand as reading, that is a process in which the text is not only taken at face-value, but that takes into account other features that create meaning from literature: context, intertextuality, polyssemy. To borrow a term from Mike Kestemont and Luc Herman, the network wants to understand whether we can model a reader.
This project stems from my PhD thesis, in which I wrote about a particular translation of Os
Lusíadas into English: the 1655 version by Richard Fanshawe, The Lusiad.
The thesis itself started as an examination of the translation in relation to its contemporary context -- a few years after the royalist deafeat in the civil war, a few years before the Restoration of Charles II -- specifically on how
Fanshawe, a stout supporter of the King, makes use of a foreign text to covertly intervene in the political debate in defense of royalism.
In the course of my research, I also did a lot of work that sits more confortably in Book History and Translation Theory, that cannot be entirely divorced from a its original text. In other words, a lot of that work is the same that a
textual editor would have done. The Lusiad edition, then, is an attempt at making that research visible and accessible, while providing a new edited text of the first English translation of the great Portuguese poem.
Although Fanshawe's The Lusiadhas been edited and re-published recently (well, 22 years
ago, but recent by academic standards), there are two major factors that make a newer edition attractive: first, since Davidson's edition, I've encountered at least one copy with autograph corrections that has not been previously
considered; and second, my proposed edition would take a different editorial principle, considering the text, first and foremost, as a translation and editing it accordingly.
Owing to my day to day responsibilities, this particular project is a little (ok, quite a bit) delayed, but it remains in my radar. Hopefully, I will have the chance to do some considerable progress in 2022.
Coding for Humanists
Coding for Humanists is a monthly study group dedicated to, well, teaching humanists how to code.
In my years working with ATNU and talking to researchers from the Humanities that wanted to do something digital with their research, I became more aware of the problems those without a technical background
face: not knowing where to begin, not knowing what is possible, the lack of of coding courses that don't automatically assume at least some degree of technical proficiency, and the lack of exercises targeted to humanities' questions: sure,
you might be able to replicate the Bernoulli Trial for a coin toss, but how is that going to help you make sense of the historical data you need to work with?
Brilliant as those resources are, self-motivated and self-directed learning is not for everyone. Even with the best of intentions, pressing responsibilities will always take precedence unless there is a scheduled time for experimenting
with coding. Even when individuals manage to set aside time to learn how to use digital methodologies for their research, there is still a couple of things missing: someone to ask questions of, and someone to bounce ideas from. Or, in other
words, a tutor and a community of learning.
It is to address these last two problems that I created Coding for Humanists. Essentially, it is a guided study group, not a course or a workshop. For the most part, each month we take a lesson from the Programming
Historian and run through it together, with me helping participants along the way and answering any questions that might arise. The uptake in the very first year surprised me: over forty registered participants! Though, of course,
not
everyone shows up everytime, which makes leading the session much easier.
For better or worst, Coding for Humanists was only available to Newcastle staff and PG students, but the experience demonstrates that there is a great appetite for this type of offer. Perhaps something for universities everywhere
to chew on.